CockroachDB Overview
Description: cockroach is an open source, survivable, strongly consistent, scale-out SQL database. If you wonder where google engineers go when they leave google, they go out on their own and build unbelievably great scalable and distributed open source software. Essentially if you want to run your own fault-tolerant SQL database across multiple datacenters and cloud services, using your own servers, allowing you complete control of your database, without paying hefty licensing fees, then run cockroach. The info in this post is not a review of cockroach, but rather a demonstration of a lab setup and POC.
To get started in our lab, first we want to build around 3 or 4 test clone servers or “nodes”. I use ubuntu on top of HyperV, but you can use any flavor of linux or MacOS you want. It can also run on Windows Docker.
If you’re like me and use Hyper-V on Win10, make 4 x Ubuntu 16.04 “clones” – first build a ‘goldmaster’ image, and clone it 4 times – guide here: https://4sysops.com/archives/clone-a-ubuntu-server-in-hyper-v-2012-r2/ – or use something like virtualboxes.org.
Create 4 virtual machines, each having it’s own IP address:
Node1: inet addr:10.0.10.169
Node2: inet addr:10.0.10.170
Node3: inet addr:10.0.10.171
Node4: inet addr:10.0.10.172
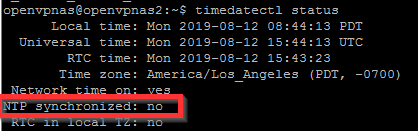
Make sure each node is up to date and has ntp installed and synchronized with the commands:
sudo apt-get install ntp
Use the command
timedatectl
To ensure that…
NTP synchronized: yes
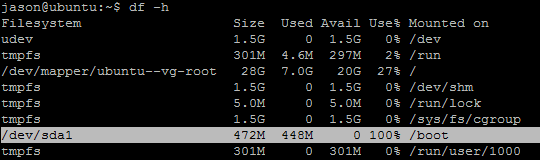
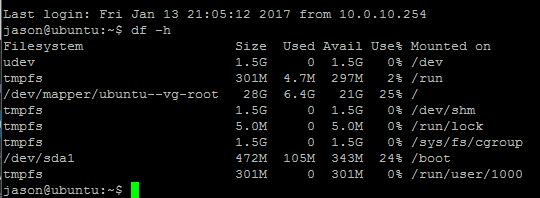
At this point before you install/run cockroach, it’s wise to export each node VM with HyperV as a backup.
On Nodes 1,2,3,4 download the latest binary here https://www.cockroachlabs.com/docs/install- cockroachdb.html with the command:
sudo wget https://binaries.cockroachdb.com/cockroach-latest.linux-amd64.tgz
Extract the binary with the command:
tar -xvf cockroach-latest.linux-amd64.tgz
Move the binary to a location in your PATH or add the directory location to your path. You can learn about your path with the command:
sudo vi /etc/environment
And then move your extracted cockroach to /usr/sbin with the command:
sudo mv cockroach-latest.linux-amd64/cockroach /usr/sbin/
Do a sanity check with the command:
cockroach version
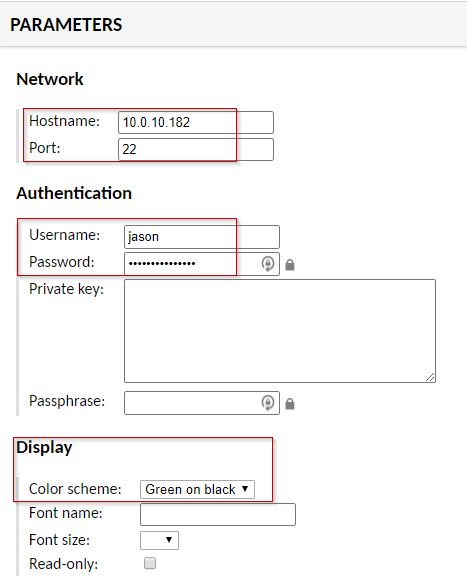
Start cockroach in insecure mode in the background on Node1 (master server) with the command:
sudo cockroach start --background --insecure --host=10.0.10.169
Result should be something like below:
CockroachDB node starting at 2017-03-15 23:16:23.118419329 -0700 PDT
build: CCL beta-20170309 @ 2017/03/09 16:31:10 (go1.8)
admin: http://10.0.10.169:8080
sql: postgresql://[email protected]:26257?sslmode=disable
logs: cockroach-data/logs
store[0]: path=cockroach-data
status: restarted pre-existing node
clusterID: 08b6bfe6-4886-466b-a9c6-bc58a3809113
nodeID: 1
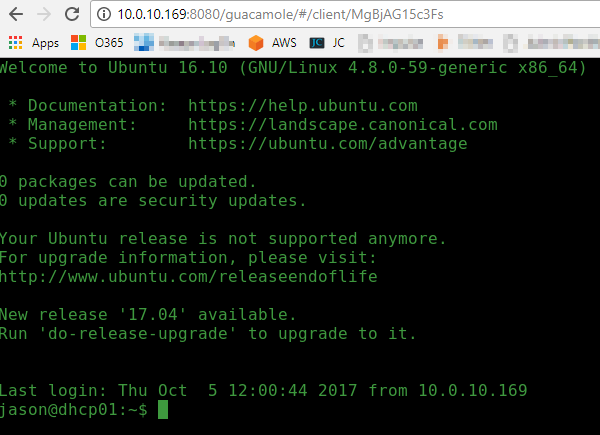
Go ahead and browse to the admin page http://10.0.10.169:8080
On your other nodes:
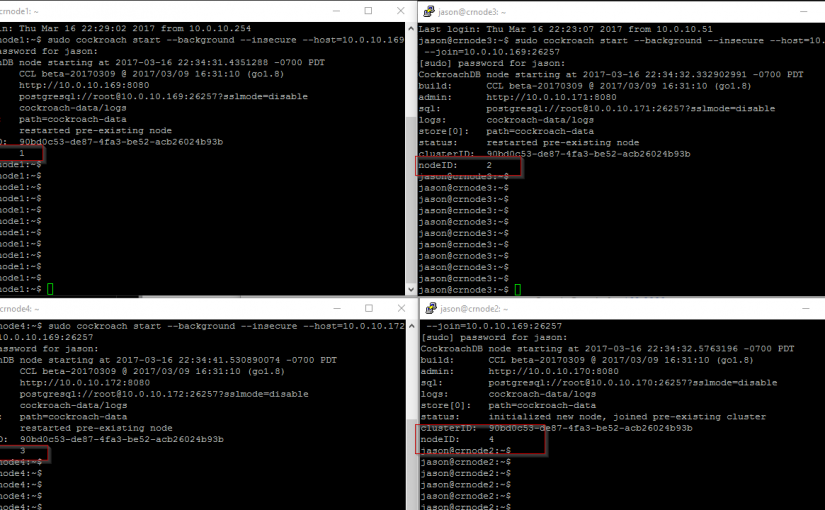
sudo cockroach start --background --insecure --host=10.0.10.170 --join=10.0.10.169:26257
*where –host=current node ip address you’re having to join with the master server 10.0.10.169
Your results should look something like the following:
CockroachDB node starting at 2017-03-15 23:23:43.783097234 -0700 PDT
build: CCL beta-20170309 @ 2017/03/09 16:31:10 (go1.8)
admin: http://10.0.10.170:8080
sql: postgresql://[email protected]:26257?sslmode=disable
logs: cockroach-data/logs
store[0]: path=cockroach-data
status: initialized new node, joined pre-existing cluster
clusterID: 08b6bfe6-4886-466b-a9c6-bc58a3809113
nodeID: 2
Your web interface should provide you with performance graphs:
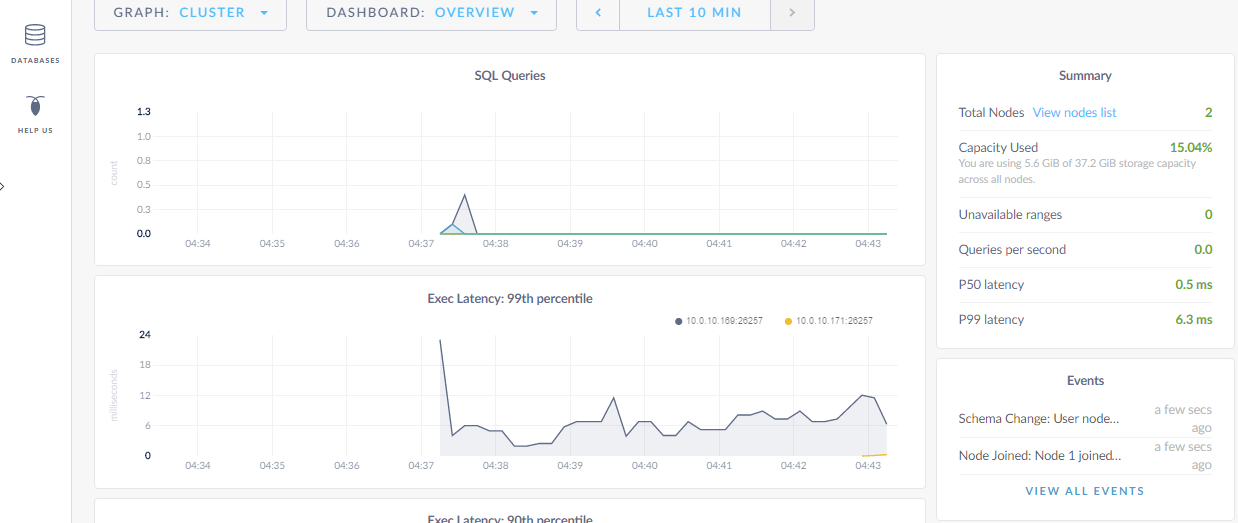
Identify the new nodes in the View Nodes List link:
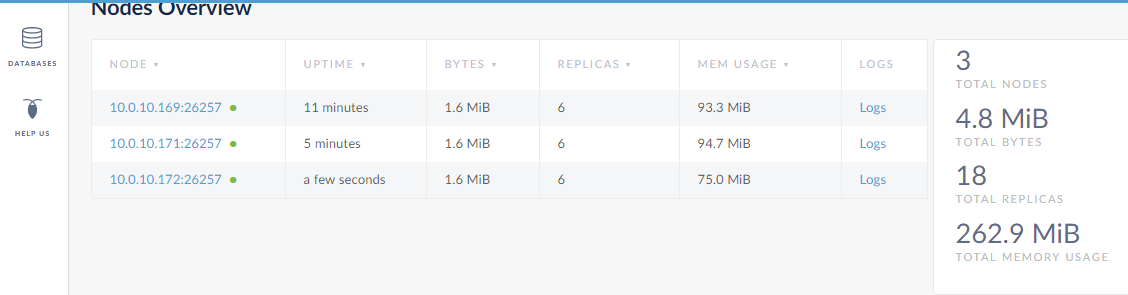
Go on and add the remaining Nodes to the cluster.
???
Profit! – just kidding
Now you can go on to learn about cockroach SQL and create some databases and tables and test how pulling the plug on one of your nodes doesn’t bring down the DB, and how all the data is replicated to all 4 nodes. It’s recommended you don’t run this lab on a single workstation-class system, but something that meets the cockroach DB minimum system requirements. This product is still in beta and features are subject to change. Regardless, cockroachdb is an incredible addition to the open-source community and I’m sure will be very useful to a lot of systems admins and application developers.