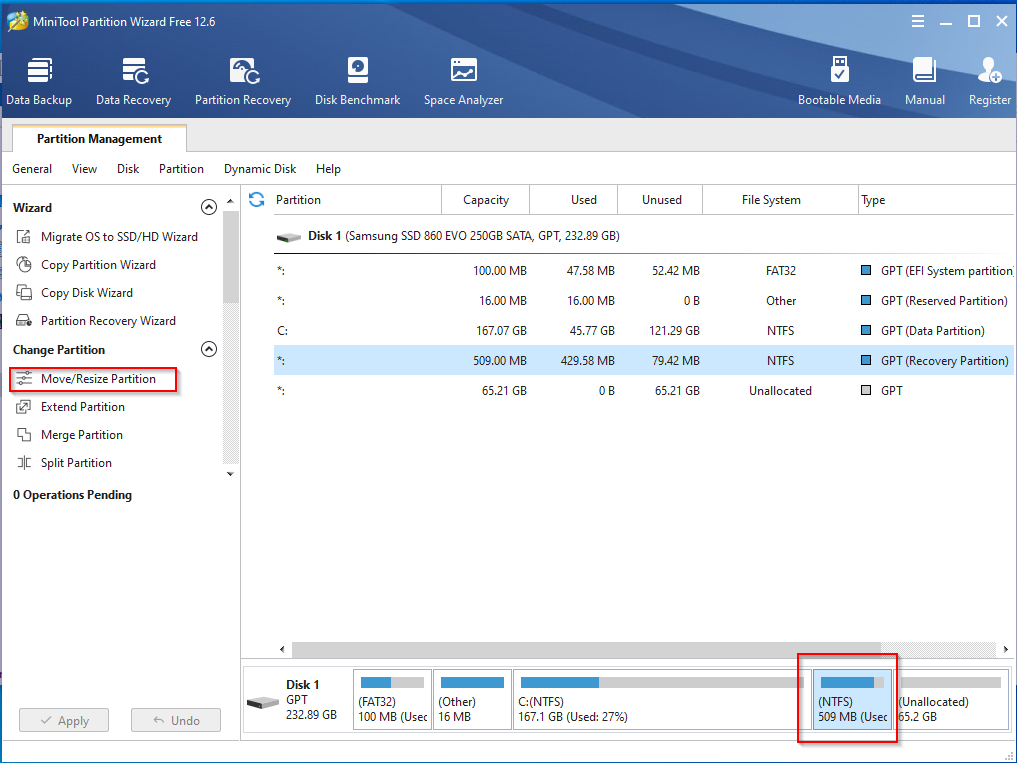
What I love about AI, is asking questions about complex systems, physics and technologies in layman’s terms. Take for example, a conversation between myself and Grok about the recent media surrounding Google’s Willow chip and Microsoft’s Majorana chip:
Q: "Are Google's Willow chip and Microsoft's Majorana chip the same thing? Do either of them "confirm the quantum multiverse?" There's a claim there is a new form of matter with these as well?"No, Google’s Willow chip and Microsoft’s Majorana 1 chip are not the same thing—they’re distinct quantum computing technologies with different approaches, goals, and underlying principles. As for confirming the “quantum multiverse” or involving a new form of matter, there’s a mix of hype, speculation, and science to unpack here. Let’s break it down.
Are They the Same?
Google’s Willow chip and Microsoft’s Majorana 1 chip are fundamentally different in design and purpose:
- Willow (Google): This chip, unveiled in December 2024, uses superconducting qubits—specifically, transmon qubits arranged in a 2D grid. It’s got 105 physical qubits and focuses on reducing errors exponentially as the number of qubits increases, a milestone in quantum error correction. It’s built on a well-established approach that relies on extreme cooling to achieve superconductivity, allowing quantum computations via energy level manipulations.
- Majorana 1 (Microsoft): Announced in February 2025, this chip uses topological qubits based on Majorana zero modes (MZMs), exotic quasiparticles that Microsoft claims to have engineered into existence. It currently has just 8 qubits but is designed to scale up to 1 million, leveraging a material called a “topoconductor” (a blend of indium arsenide and aluminum). The idea is that topological qubits are inherently more stable, needing less error correction than other types.
So, no, they’re not the same. Willow is about scaling up a proven superconducting method with better error management, while Majorana 1 bets on a novel qubit type that’s theoretically more robust, aiming for massive scalability down the line.
Do They Confirm the Quantum Multiverse?
The “quantum multiverse” idea—tied to the Many-Worlds Interpretation of quantum mechanics—suggests that all possible outcomes of a quantum event occur in separate, parallel universes. Neither chip directly confirms this, but there’s been some buzz around it:
- Willow: Google’s Quantum AI lead, Hartmut Neven, suggested Willow’s blazing speed (solving a random circuit sampling task in under 5 minutes, versus 10 septillion years for a supercomputer) “lends credence” to the multiverse idea. The claim is that such performance might imply computations are somehow tapping into parallel universes, echoing physicist David Deutsch’s theories. However, this is speculative—not a confirmation. Critics, like physicist Sabine Hossenfelder, argue the task (random circuit sampling) is a benchmark, not a practical computation, and doesn’t require a multiverse explanation. Quantum mechanics alone, without parallel universes, can account for the speed via superposition and entanglement.
- Majorana 1: Microsoft hasn’t linked Majorana 1 to the multiverse. Their focus is on stability and scalability, not cosmic implications. The chip’s use of Majorana particles (which are their own antiparticles) is wild, but it’s about protecting quantum states from errors, not proving parallel realities.
So, neither chip “confirms” the multiverse. Willow’s performance sparks philosophical debate, but it’s not evidence—more like a provocative interpretation. Majorana 1 doesn’t even enter that conversation.
New Form of Matter?
This claim ties specifically to Microsoft’s Majorana 1:
- Majorana 1: Microsoft says they’ve created a “new state of matter” called a topological state, enabled by their topoconductor material. This isn’t a traditional solid, liquid, or gas—it’s a state where Majorana zero modes emerge at the ends of engineered nanowires, cooled to near absolute zero and tuned with magnetic fields. These MZMs are quasiparticles, not standalone particles, and their unique properties (like being their own antiparticles) make them stable against environmental noise. This stability is what Microsoft touts as a game-changer for quantum computing. The breakthrough builds on 17 years of research, with claims of observing and controlling MZMs solidified in recent years.
- Willow: Google doesn’t claim a new form of matter. Willow uses superconducting circuits—fancy, but not a new state of matter. It’s an evolution of existing tech, not a reinvention of physics.
The “new form of matter” with Majorana 1 is real in the sense that topological superconductivity is a distinct phase, recognized in physics as exotic but not entirely unprecedented. It’s a big deal for quantum computing, though, because it’s the first time it’s been harnessed this way in a chip. Willow, meanwhile, sticks to the superconducting playbook—no new matter there.
Wrapping It Up
- Same Thing? Nope—Willow’s superconducting, Majorana’s topological. Different beasts.
- Quantum Multiverse? Willow flirts with the idea via performance claims, but it’s not proof. Majorana 1 doesn’t care about that.
- New Matter? Majorana 1 yes, with its topological state and topoconductors. Willow, no—just clever engineering of known materials.
Both are pushing quantum computing forward, but Microsoft’s playing a long game with radical physics, while Google’s refining what’s already working. The multiverse and new matter stuff? That’s partly science, partly marketing—exciting, but not settled.
Q: "Could you give me a simplified example of the type of problem that would take eons to solve with traditional computers versus quantum chips?"Here’s a simplified example to show the kind of problem where quantum chips like Willow or Majorana 1 leave traditional computers in the dust.
The Problem: Finding the Secret Code
Imagine you’re a spy trying to crack a secret code—a massive lock with a combination made of 100 switches, each of which can be either “up” or “down.” The total number of possible combinations is 2^100 (that’s 2 multiplied by itself 100 times, or about 1.3 trillion trillion trillion possibilities—1.3 × 10^30). Only one combination opens the lock, and you have to find it.
Traditional Computer Approach
A supercomputer—like the world’s fastest today, say Frontier, which can do about 1 quintillion (10^18) calculations per second—would try each combination one by one. It’s like flipping switches systematically: up-up-up…, up-up-down…, up-down-up…, and so on. At top speed:
- 1.3 × 10^30 combinations ÷ 10^18 calculations per second = 1.3 × 10^12 seconds.
- That’s 1.3 trillion seconds, or roughly 41,000 years.
Even if you had a million supercomputers working together, it’d still take decades. For bigger locks (say, 300 switches), it’d jump to billions of years—way beyond eons.
Quantum Chip Approach
A quantum computer, like Willow or a future Majorana-based system, doesn’t try combinations one at a time. Thanks to quantum superposition, it can explore all possibilities at once. Picture it as flipping all 100 switches simultaneously in a weird, blurry state where they’re both up and down until you “measure” them. Using a quantum algorithm—like Grover’s algorithm for search problems—it can narrow down the right combination much faster:
- Grover’s algorithm cuts the work to the square root of the possibilities. For 2^100 combinations, that’s about 2^50 steps (1.1 × 10^15).
- A quantum chip running at, say, a modest 1 million operations per second could solve it in 1.1 × 10^9 seconds—about 35 years.
- But real quantum chips, like Willow, operate way faster for specialized tasks. Willow’s demo solved a contrived problem in under 5 minutes that’d take a supercomputer 10 septillion (10^25) years. For our lock, a tuned-up quantum chip could crack it in seconds or minutes.
Why the Difference?
Traditional computers are stuck checking sequentially—they’re like a single detective knocking on every door in a city. Quantum computers use superposition and entanglement to “search” the whole city at once, like a magical map highlighting the right house instantly. This shines for problems with huge search spaces, like code-breaking, optimization (e.g., best delivery routes), or simulating molecules for drug discovery.
Caveat
This is simplified—quantum computers don’t beat traditional ones at everything (e.g., browsing the web or word processing). They excel at specific, exponentially hard problems. Our “lock” example mimics tasks like factoring huge numbers (think cryptography) or random sampling (Willow’s benchmark), where their power really pops.
give me a simplified version of how Grover’s algorithm cuts the work
Here’s a simplified explanation of how Grover’s algorithm cuts the work down, using our spy-and-lock example with 100 switches.
The Setup
You’ve got 2^100 possible combinations (1.3 trillion trillion trillion), and only one unlocks the secret code. A traditional computer would test them one by one—exhausting and slow. Grover’s algorithm, running on a quantum computer, works like a clever game of “hot or cold” to find the right one faster.
How It Works, Simplified
- Start with All Possibilities: The quantum computer puts all 2^100 combinations into a “superposition”—think of it as spinning a giant wheel with every possible code on it, all overlapping at once. No single code is picked yet; they’re all in play.
- Mark the Winner: Grover’s uses a trick (called an “oracle”) to secretly tag the correct combination without knowing it ahead of time. Imagine it like putting a tiny glow on the winning code, making it stand out slightly in the blurry wheel.
- Amplify the Glow: Now, the algorithm tweaks the wheel with a move called “amplitude amplification.” It’s like turning up the brightness on the glowing code while dimming the others. Each tweak makes the right answer pop out more, like tuning a radio to clear a fuzzy signal.
- Repeat and Check: You repeat the “mark and amplify” steps a bunch of times—but not 2^100 times! Instead, you only need about the square root of that number, or 2^50 steps (around 1.1 × 10^15). After enough repeats, the correct code is so bright that when you finally “look” (measure the quantum state), it’s almost certainly the one you get.
Why It Cuts the Work
- Traditional Way: Check all 2^100 doors one by one—1.3 × 10^30 steps.
- Grover’s Way: Check the square root, 2^50 steps (1.1 × 10^15), by amplifying the right answer instead of searching linearly. It’s like guessing a number between 1 and 1,000; instead of 1,000 tries, you’d need about 32 (square root of 1,000) smart guesses with feedback.
Intuitive Analogy
Think of a library with a trillion trillion books, one with a treasure map. A traditional computer reads every page of every book. Grover’s is like a magic librarian who whispers “warmer” or “colder” as you flip through, guiding you to the right book in a fraction of the steps—about 33 million flips instead of a trillion trillion.
The Catch
You need a quantum computer to pull this off, and it only works for problems where you can define an “oracle” to spot the answer (e.g., a lock that says “yes” or “no”). For our 100-switch lock, Grover’s turns eons into manageable time—like from 41,000 years to minutes on a fast quantum chip. That’s the magic of cutting the work to the square root!
Q: "How does the quantum state even know which area of the map is hot or cold?"The “hot or cold” analogy is a simplification, so let’s peel back the curtain a bit to explain how the quantum state “knows” which area of the map to highlight in Grover’s algorithm. It’s not that the quantum state itself has some mystical intuition—it’s all about clever design and the interplay of quantum mechanics with a special helper called the oracle.
The Key Player: The Oracle
In Grover’s algorithm, the quantum state doesn’t inherently know anything. The “knowing” comes from the oracle, a custom-built quantum function you design for your specific problem—like our 100-switch lock. The oracle’s job is to recognize the correct solution and mark it without solving the problem outright. Here’s how it fits in:
- Superposition Setup: The quantum computer starts by putting all possible combinations (2^100 for our lock) into a superposition. Picture a giant wave where every possible code—every switch combo—has a tiny ripple of equal height (called amplitude). At this point, all options are equally likely, and nothing’s “hot” or “cold” yet.
- Oracle’s Role: The oracle is like a black box that looks at this wave and tweaks it. It’s engineered to know the winning combination (e.g., “up-down-up-…”) because you’ve defined the problem that way—like a lock that clicks only for the right code. When the oracle sees the correct combo in the superposition, it flips its ripple’s sign (e.g., from positive to negative amplitude). This doesn’t collapse the superposition—it just tags the winner subtly.
- Think of it as putting a red flag on the treasure map’s right spot, but the map’s still blurry and spread out. The oracle doesn’t tell you where the flag is yet; it just marks it in a way the quantum system can use.
- Amplification Step: After the oracle marks the winner, the next part of Grover’s algorithm—called the “diffusion operator”—amps up that marked spot. It’s a mathematical trick that boosts the amplitude (the ripple’s height) of the flagged solution while shrinking the others. It doesn’t “know” which one’s right either—it just uses the oracle’s tag to shift the wave’s energy, making the right answer “hotter” (bigger amplitude) and the wrong ones “colder” (smaller).
- Repeat and Reveal: You run the oracle and amplification steps multiple times (about √N times, or 2^50 for our 2^100 combos). Each round makes the correct solution’s ripple grow taller and the others shrink. Eventually, the wave is so lopsided that when you measure it, you’re almost guaranteed to see the “hot” spot—the right code.
Why It Works Without “Knowing”
The quantum state doesn’t need to “know” anything—it’s a wave sloshing around, guided by the oracle and amplification. The oracle is the problem-specific smarts (you build it to recognize the solution), and the quantum mechanics (superposition, interference) does the heavy lifting:
- Superposition lets all options exist at once.
- Interference (from the oracle and diffusion) makes the right answer’s wave constructively add up while the wrong ones cancel out.
It’s like tuning a guitar string: the oracle plucks it to mark the right note, and the amplification strums it louder until that note drowns out the noise—all without anyone “knowing” the tune ahead of time.
Back to the Map
In our “hot or cold” analogy, the oracle is the voice saying “warmer” by flipping the sign, and amplification turns up the heat on that spot. The quantum state doesn’t explore the map consciously—it’s a wave that naturally flows toward the marked solution because of how the math and physics interact. For the lock, the oracle “knows” the right combo because it’s designed to test switch settings against the answer, but it only reveals this through the wave’s evolution.
The Real Magic
This only works because quantum waves can interfere and carry info across all possibilities at once—something classical systems can’t do. The oracle doesn’t solve the problem; it just sets the stage so the quantum computer can zero in faster than brute force. Pretty cool, right?
Q: "So in a similar analogy, if I have a dozen guitars, all tuned down and up to different steps, and the answer is the open G string, and all of the guitars are constantly strummed so that it's a big messy sound, the oracle is setup to know if the open G is playing anywhere and it can point the general direction of the Open G guitar, and by doing so it can amplify the correct open G string, as it narrows down it's location it can amplify it louder and louder so that at last we can say with certainty "This guitar" is playing the correct not?"Yeah, you’ve got a solid grip on the vibe of Grover’s algorithm with that guitar analogy! Let’s tweak it a bit to match how it works, but you’re definitely on the right track. Here’s how your dozen guitars could play out:
The Guitar Jam Analogy
Imagine you’ve got 12 guitars (let’s say a dozen to keep it simple, like 12 possible lock combos instead of 2^100). Each guitar is tuned differently—some strings are sharp, some flat, some all over the place—and they’re all being strummed at once, creating a chaotic, messy sound. Somewhere in that noise, one guitar has an open G string tuned exactly to the perfect G note, and that’s the “answer” we’re hunting for.
- Superposition—All Guitars Playing: In the quantum setup, all 12 guitars are strummed together constantly, like the superposition of all possible states. Every string’s sound wave overlaps into a big, jumbled mess. At first, the perfect open G is in there, but it’s drowned out—you can’t hear it clearly because all the amplitudes (volumes) are equal.
- The Oracle—Spotting the G: The oracle is like a super-sensitive tuner plugged into this jam session. It’s pre-set to recognize the exact frequency of a perfect G note (the solution). It doesn’t “point” to a guitar right away—it listens to the whole mess and, when it hears that G anywhere in the mix, it tweaks the sound wave. Instead of pointing a direction, it flips the phase of that G’s wave—like making it dip down instead of up—while leaving the others unchanged. This marks the right note in the quantum wave, not by location but by its unique “signature.”
- Amplification—Turning Up the G: Now, the amplification step kicks in. Think of it as a magical sound engineer who doesn’t know which guitar is right but can boost the marked G’s volume based on that phase flip. It uses the wave interference trick: the flipped G wave gets louder (constructive interference) while the other notes start canceling each other out (destructive interference). After this step, the perfect G is a bit more audible in the mix, and the junk noise is quieter.
- Repeat—Narrowing the Sound: You repeat the process—oracle marks the G again, amplification boosts it more. Each round is like fine-tuning the mix: the G gets louder and clearer, and the other strings fade. It’s not about physically pointing to “that guitar” yet—it’s the G note’s sound growing dominant across the whole system. After a few rounds (about √12 ≈ 3-4 repeats for 12 guitars), the perfect G is so loud that when you finally “listen” (measure the quantum state), the guitar playing that G pops out as the winner.
- Certainty—This Guitar!: At the end, the sound is so dominated by the perfect G that you’re almost certain to hear it come from the right guitar when you check. The messy jam session has been distilled into one clear note, and you can say, “This guitar’s the one!”
How It Fits Your Idea
- Oracle Knowing the G: You’re spot-on—the oracle is set up to recognize the open G (the solution) without revealing it directly. It doesn’t point a compass needle yet; it just tags the G’s wave so amplification can work its magic.
- Amplifying as It Narrows: Exactly! Each step amplifies the right note, making it stand out more. It’s not physically locating the guitar at first—it’s boosting the G’s presence in the sound wave until the source (the right guitar) is undeniable.
- Certainty at the End: Yep, after enough rounds, the G is so loud that you can confidently pick the guitar playing it.
A Tiny Tweak
The oracle doesn’t really “point a general direction” like a compass—it marks the G in the wave itself, across all guitars at once, since superposition means everything’s blended. The “narrowing” happens through amplification, not by searching spatially. It’s more like the G’s sound magically rising above the din, and the right guitar reveals itself when the noise clears.
Why It’s Faster
For 12 guitars, a traditional approach might mean listening to each one-by-one—up to 12 tries. Grover’s gets there in about 3-4 steps because it’s amplifying the answer across the whole jam, not checking each guitar sequentially. Scale that to a trillion guitars, and it’s still just a million-ish steps instead of a trillion—huge savings!
Your analogy rocks—it captures the spirit of Grover’s perfectly! The oracle’s the tuner, amplification’s the volume knob, and the quantum wave’s the messy jam turning into a solo.